I am one of the people who implemented the language selector on Wikipedia, one of the World Wide Web’s most multilingual sites. Because of that, and because I’ve loved languages since I was five, I’m generally obsessed with language selection interfaces everywhere: websites, apps, self-service kiosks, airplane entertainment systems, cars, smart headphones, and so on.
So I was obviously thrilled to see a language selector as a minor plot device in the movie Atlas starring Jennifer Lopez. Most movie critics were quick to pan it, but I’m occasionally curious about “so bad it’s good” movies and like many other people these days, I’m curious about the portrayal of artificial “intelligence” in art, so I bothered to watch it. It is indeed not too brilliant: J.Lo’s acting is pretty OK, and the story has some sensible ideas about AI, but it also has ideas that are very silly and self-contradicting, as well as too much CGI, too many references to the Terminator, Alien, and Blade Runner franchises, and a generally lazily-written script. Though it’s mildly entertaining, you probably have better ways to spend two hours.
However, if I don’t write something about the language selector there, who will? So let’s go:
A screenshot from Netflix. A futuristic interface for selecting languages: three columns of buttons with names of languages and flags. At the top, a closed caption: “Francais [speaks French]”. The other details are described in the rest of the post.
This selector appears at about 33 minutes into the movie.
A few general comments first.
Representing languages using flags is common in language selection interfaces, but it’s a very bad practice. This interface has many examples of why it’s bad, which I’ll discuss in detail.
If my calculations are correct, the movie mostly takes place in the year 2071. The language selector is designed to look like something from that year, but it actually looks a lot like a language selector from a contemporary video game, for example Brawl Stars:
(I’m not much of a gamer, but I’ve got a feeling that there are games whose language selectors are even more similar to the one in Atlas. If you have an example, let me know.)
Some of the languages in the Atlas selector are unusual and don’t quite exist as separately-named languages today. Are the producers suggesting that they’ll exist as independent software user interface languages in 2071? Are those inside jokes by people in the production crew? Are those just goofs? I don’t know, but I’ll try to add a few guesses along the way. Please remember that those are just guesses.
I am failing to find logic in the order of the languages. It’s not alphabetical by the original language name, not by the English language name, not by ISO language code. Maybe it’s just random. Maybe it’s based on some currently-existing software. I just don’t know.
And of course, it’s generally weird that any software in 2071 needs a manual language selector, especially in the context shown in the film—setting up a piece of electronic equipment after turning it on for the first time. Already today, automatic language detection works fairly well in both text and audio, so by 2071, manual selection should be completely unnecessary. Perhaps the producers wanted to poke fun at modern software instead of showing how it will actually look like in 2071.
Now, let’s finally take a look at the languages themselves, going by columns from left to right.
Right at the top, we have something quite odd. The label says “Hejazi”. It’s written in broken Arabic because the designers, as it very often happens, didn’t bother to ask native speakers to proofread. The letters appear disconnected and are written from left to right, and not from right to left. The flag is a bit similar to the Palestinian, Jordanian, and Sudanese flags, but with a different order of colors. According to Wikipedia, it was indeed used by the Kingdom of Hejaz, a short-lived country that existed for a few years after the First World War, and eventually merged with Saudi Arabia. Hejaz is a geographical region in the West of the Arabian Peninsula, and a particular variety of Arabic is spoken there, but to the best of my knowledge, the people who speak it mostly write in standard Arabic, which is treated separately here (more on that later).
Next we have German and Spanish, about which there isn’t much to add except that those languages are represented by the flags of Germany and Spain, even though both languages are spoken in multiple countries.
Chinese is also mostly uneventful—it uses the PRC flag and is just labeled “Chinese”, without “traditional” and “simplified” in parentheses.
Portuguese is represented by the flag of Brazil, even though it’s also spoken in Portugal, Angola, Mozambique, and several other countries.
Then we have Turkish, Tagalog, and Ukrainian, about which there’s not much to say, except that Ukrainian is present here, but Russian isn’t! Does it mean anything? No idea.
Not much to say about Czech and Italian.
English is represented by the United States flag and not by England, U.K., or India (which, depending on how you count, may be the nation with the largest number of English speakers). I don’t understand why is Spanish represented by a European country, while English and Portuguese are represented by American countries.
Not much to say about Korean, Swedish, and Japanese, but there’s a comment about Swedish later.
Finnish is labeled “Suomalainen”. This word describes a Finnish person, and is also used as the adjective “Finnish” for describing some things, but not the Finnish language.
Then we have “Arabic”. Like Hejazi, it’s written from left to right and in disconnected letters. The flag is fuzzy, but it’s probably the UAE one. Arabic is spoken in many countries, and over the years, I’ve seen lots of flags representing the Arabic language: Saudi Arabia’s Shahada flag, Palestinian, Jordanian, or UAE flags, the Arabic letter Ayin, etc.
“Bajan” is the Barbadian creole. Today it is spoken by many people, but not written much. Was there someone Barbadian in the filming crew? Does anyone suggest that it will be a big established language used in software user interfaces in 2071 or is it just a joke? (I didn’t know that “Bajan” is a word for describing the Barbadian culture before watching the film, and it’s probably the most useful thing I learned from it.)
Hausa is represented by the flag of Nigeria. This language is also spoken in Niger and in some other countries. It’s one of the world’s biggest languages, and it’s particularly important in all of Western Africa. Nigeria is a heavily multilingual country, and Hausa is just one of its four big languages, the other three being Yoruba, Igbo, and Fula. So it’s not a very good idea to use the Nigerian flag for this.
Catalan is represented by the Catalan independence activists’ flag, with the blue chevron and the star, known as Estelada. The official flag of the autonomous community of Catalonia is just the yellow one with the four red stripes, and it will probably remain its flag if it ever becomes independent. Are they hinting that Catalonia will achieve independence by 2071? Paying tribute to the fact that Catalan is heavily present in many websites and apps? Or just being ignorant?
“Kryuol” is the Jamaican English-based creole. I didn’t know that “Kryuol” is one of its names, but it looks like it appears on some websites, such as this, so it’s probably not a mistake. Like Barbadian, it’s not written much these days, but maybe it will be written more in the future.
“Sranan” is the language of Suriname, a creole based mostly on English and Dutch. There is a Wikipedia in it, but I haven’t seen it written elsewhere.
Next comes one of the oddest entries: “Åland”. Today, it is a name of an island, which is a Swedish-speaking self-administering territory of Finland. About thirty thousand people live there. There is an Åland Swedish dialect, and I cannot say how different it is from standard Swedish, which appears in this selector separately. Will it develop to an independent language by 2071? Maybe, but it’s still odd to see it in the list. Maybe Åland and Suriname will be revealed as the world centers of AI innovation in the sequel? (Netflix, if you’re producing a sequel and use this idea, consider giving me a lifetime ad-free subscription or something.)
And the last one is Azerbaijani. It’s written strangely. Like the names of other languages, its name is written in all-caps: “AZƎRBAYCANLI”. The third letter is Ǝ, which is the capital counterpart of ǝ. It is incorrect, because the name of this language must be written with the letter Ə, which is the capital counterpart of… ə! The small letters look the same, but the capital letters are different. It’s one of most confusing things in the extended Latin alphabet, and the production designers fell for this trap. Also, the name of the language is usually written with the suffix -CA and not the suffix -LI. As it is with the name of the Finnnish language in the same screen, this word is more appropriate for an Azerbaijani person than for the Azerbaijani language.
So there. Some of the issues are usual and common today: broken Arabic, and wrong character for Azerbaijani.
The most surprising thing is probably the dialects or creoles that are minor or barely existing today: Åland, Hejazi, Bajan, Sranan, Kryuol. Not something that is seen often. Since some of them are Caribbean, perhaps it’s Lopez’s tribute to her Puerto Rican background? But then why aren’t Haitian Creole and Papiamento there, considering that they are much more prominent? I have no answer.
If you see a language selector in any other movies or in any other interesting place, please let me know!
I was wondering: In which languages, user interface translations tend to be longer, and in which ones they are shorter?
The intuitive answers to these questions are that Chinese and Japanese are very short, English tends to be shorter than the average, Hebrew is shorter than English, and the longest ones are Turkish, Finnish, German, and Tamil. But what if I try to find a more precise answer?
So I made a super-simplistic calculation: I checked the average length of a core MediaWiki user interface message for English and the 150 languages with the highest number of translations.
I sorted them from the shortest average length to the longest. The table is at the end of the post.
Here’s a verbal summary of some interesting points that I found:
The shortest messages are found, unsurprisingly, in Chinese, Japanese, and Korean.
Another group of languages that surprised me by having very short translations are some Arabic-script languages of South Asia: Saraiki, Punjabi, Sindhi, Pashto, Balochi.
Three more languages surprised me by being at the shoter end of the list: Hill Mari (mhr) and Northern Sami (se), which are Finno-Ugric, a family known for agglutinative grammar that tends to make words longer; and Armenian, about which I, for no particular reason, had the impression that its words are longish.
English is at #22 out of 151, with an average length of 38.
Hebrew is slightly above English at #21, with 37.9. This surprised me: I was always under the impression that Hebrew tends to be much shorter.
The longest languages are not quite the ones I thought! The longest ones tend to be the Romance languages: Lombard, French, Portuguese, Spanish, Galician, Arpitan, Romanian, Catalan.
Three Germanic languages, namely Colognian, German and Dutch, are on the longer end of the list, but not all of them. (Colognian is the longest in my list. The reason for this is not so natural, though: The most prolific translator into it, User:Purodha, liked writing out abbreviations in full, so it made many strings longer than they could be. He passed away in 2016. May he rest in peace.)
Other language groups that tend to be longer are Slavic (Belarusian, Russian, Bulgarian, Polish, Ukrainian) and Austronesian (Sakizaya, Ilokano, Tagalog, Bikol, Indonesian).
Other notable, but not easily grouped languages that tend to be longer are Irish, Greek, Shan, Quechua, Finnish, Hungarian, Basque, and Malayalam. All of them have an average length between 45 and 53 characters.
Turkish is only slightly above average with 44.1, at #88.
Tamil is a bit longer, with an average length of 44.6, at #94. Strings in its sister language Malayalam are considerably longer, 49.1.
The median length is 43, and the average for everyone is 42. Notable languages at these lengths are Mongolian, Serbian, Welsh, Norwegian, Malaysian, Esperanto, Georgian, Balinese, Tatar, Estonian, and Bashkir. (Esperantistoj, ĉu vi ĝojas aŭdi, ke via lingvo aperas preskaŭ ĝuste en la mezo de ĉi tiu listo?)
One important factor that I didn’t take into account is that, for various reasons, translators to different languages may select to translate different messages, and one of those reasons may be that people choose to translate shorter messages first because they are usually easier. I addressed this in a very quick and dirty way, by ignoring strings longer than 300 characters. Some time in the (hopefully near) future, I’ll try to make a smarter way to calculate it.
And here are the full results. Please don’t take them too seriously, and feel free to write your own, better, calculation code!
#
Language code
Average translation length
1
zh-hans
17.67324825
2
zh-hant
18.52284388
3
skr-arab
21.81899964
4
ja
24.67007612
5
ko
25.8110372
6
sd
27.71960396
7
mhr
28.95451413
8
ps
32.73647059
9
pnb
33.03592163
10
bgn
34.39934667
11
se
34.69274476
12
hy
35.02317597
13
su
35.37706967
14
th
35.52957892
15
ce
35.6969602
16
mai
36.02093909
17
lv
36.14100906
18
gu
36.59380971
19
bcc
36.64866033
20
fy
37.60139287
21
nqo
37.94138834
22
he
37.95259865
23
en
38.04300371
24
ar
38.18569036
25
ckb
38.66867672
26
min
38.71156958
27
ses
38.87941712
28
jv
38.94753377
29
is
39.0652467
30
alt
39.39977435
31
az
39.4337931
32
kab
39.50967506
33
tk
39.54990758
34
mr
39.72049689
35
as
39.72080166
36
sw
39.73986071
37
km
39.77591036
38
azb
39.92411642
39
nn
39.96771069
40
yo
40.00503291
41
io
40.0528125
42
af
40.1640678
43
blk
40.2813059
44
sco
40.33289474
45
diq
40.33887373
46
yi
40.34033476
47
ur
40.39857651
48
ug-arab
40.53965184
49
da
40.55894826
50
my
40.67551519
51
kk-cyrl
40.87443182
52
guw
41.07080182
53
mg
41.08369028
54
sq
41.23219241
55
fa
41.27007299
56
or
41.27020202
57
ne
41.33971151
58
rue
41.40219378
59
lfn
41.54527278
60
lrc
41.61281337
61
sah
41.63293173
62
vi
41.74578313
63
awa
41.84093291
64
hi
41.9257885
65
si
41.93065693
66
te
41.99780915
67
mn
42.18728223
68
lki
42.21091396
69
bjn
42.57961538
70
sr-ec
42.67730151
71
cy
42.75020408
72
frr
42.92761394
73
vec
43.00573682
74
sr-el
43.13764389
75
nb
43.34987835
76
krc
43.54919554
77
ms
43.5553814
78
hr
43.55564807
79
eo
43.57477789
80
nds-nl
43.59060895
81
ka
43.60108696
82
ban
43.64178033
83
bs
43.681094
84
tt-cyrl
43.78230132
85
xmf
43.80860161
86
et
43.96494239
87
ba
43.99432099
88
tr
44.17996604
89
bn
44.28768449
90
bew
44.44706174
91
sv
44.49027333
92
sa
44.58670931
93
cs
44.59026764
94
ta
44.62803055
95
mt
44.70207417
96
lt
44.7615
97
roa-tara
44.79812466
98
fit
44.79824561
99
dsb
44.9151957
100
hsb
44.96197228
101
br
44.98873461
102
sh-latn
45.00976709
103
fi
45.1222031
104
hu
45.17139303
105
sk
45.35804702
106
lb
45.39073034
107
li
45.5539548
108
id
45.56471159
109
gsw
45.63605209
110
sl
45.75350606
111
be
45.80325
112
oc
45.85709988
113
mk
45.90943939
114
bcl
45.97070064
115
scn
46.11905532
116
an
46.14892665
117
uk
46.22955524
118
qu
46.30301842
119
eu
46.33589404
120
lij
46.660536
121
pl
46.76863316
122
hrx
46.79802761
123
ast
46.87204161
124
nap
46.93783147
125
ru
47.02326139
126
bg
47.03590259
127
be-tarask
47.28525242
128
hif-latn
47.41652614
129
tl
47.51263001
130
rm
47.60741067
131
pms
47.69805527
132
pt-br
47.84063647
133
ca
47.92468307
134
ro
48.22437186
135
nl
48.4175636
136
ia
48.48612816
137
it
48.52347014
138
frp
48.54542755
139
gl
48.57820482
140
ml
49.12108224
141
es
49.21062944
142
pt
49.63085602
143
de
49.77225067
144
szy
49.84650877
145
shn
49.92356241
146
fr
50.15585031
147
lmo
50.85627837
148
ilo
50.9798995
149
el
51.14834894
150
gd
51.72994269
151
ksh
53.36332609
The Python 3 code I’ve used to create the table. You can run in the root directory of the core MediaWiki source tree. It’s horrible, please improve it!
import json
import os
import re
languages = {}
code_re = re.compile(r"(?P<code>[^/]+)\.json$")
def process_file(filename):
code_search = code_re.search(filename)
code = code_search.group("code")
if code in ('qqq', 'ti', 'lzh', 'yue-hant'):
return
with open(filename, "r", encoding="utf-8") as file:
data = json.load(file)
del(data['@metadata'])
average_unicode_length(code, data)
def average_unicode_length(language, translations):
total_translations = len(translations)
if total_translations < 2200:
print('Language ' + language + ' has fewer than 2200 translations')
return
total_length = 0
for translation in translations.values():
if len(translation) < 300:
total_length += len(translation)
# Calculate the average length
average_length = total_length / total_translations
languages[language] = average_length
root = "./languages/i18n/"
for file in os.listdir(root):
if file.endswith(".json"):
path = os.path.join(root, file)
process_file(path)
sorted_languages = sorted(
languages.items(),
key=lambda item: item[1]
)
# Print the sorted items
for code, length in sorted_languages:
print(code, '\t', length)
The closure of a Wikipedia sounds like an unfortunate and negative thing, but sometimes it’s positive. The Akan Wikipedia has just been closed, and people who speak languages related to it are celebrating it. How did it happen?
In the mid-2000s, two Wikipedias were created: in Akan (ak) and in Twi (tw). I don’t know these languages, but to the best of my understanding, creating them in this manner was a mistake: Akan is a language family, and Twi is one of the languages in that family. Another notable language in the same family is Fante. They are mostly spoken in Ghana by around 20 million people; it’s hard to count more precisely for various social reasons, but in any case, that’s a lot of people.
When they were created, the people who did the technical work of creating the domains didn’t notice that “Akan” is not quite a language. There was no Language committee back then to check such matters. Some things about the quick, anarchical management of Wikipedia and stuff around it back at that time were fun and proved to be useful, but some ended up being wrong, confusing, and hard to fix.
For years, people from Ghana have been perplexed about this and asked me for assistance on clearing this situation up. Should they contribute to “Akan” or to “Twi”? And if they want to write in the Fante language, which is related, but distinct, where should they do it? Being one of the “language geeks” of the Wikimedia movement, I have been asked this repeatedly by many people: on talk pages, in e-mails and Telegram messages, in real life at Wikimania conferences.
And all the while, the amount of content in both Wikipedias was tiny and growing very slowly. In 2020, there were fewer than one thousand articles in each of them. This is really tragic, given the huge number of people who speak these languages (especially Twi). It was clear to me that the confusion about the two domains is one of the reasons for the low activity; certainly not the only reason, but definitely one of them. I tried to find people who know the language well and who can help me resolve this problem, but every time it didn’t work out; I guess people have different priorities.
It finally started changing in 2021, when I met Robert Jamal online. Initially, he was interested in making some advanced contributions to the English Wikipedia. I helped him do that, but after speaking to him a bit, I realized he knows Twi well, and asked whether he’ll be interested in contributing in that language, too. And he was! We first focused on completing the localization of the basic user interface into Twi on translatewiki.net and cleaning up the existing pages in the Twi Wikipedia. Robert also started attracting new editors, teaching them to edit, and organizing events. He also obtained the administrator rights on the Twi Wikipedia.
Then in 2022, we started dealing with the elephant in the room: the confusing Akan Wikipedia. He confirmed that all the content there is written in essentially the same language as Twi. I used my global administrator rights to delete dozens of pages that were obviously nonsensical or too short to be useful, and Robert wrote a proposal for closing that domain: gracefully copy all the remaining useful content from the Akan Wikipedia to the Twi Wikipedia and then lock it for further editing.
When you type “tw” in your browser, what do you want to see in the autocompletion?
Other people who know Akan languages expressed their opinion about that proposal, and there was clear consensus to implement it. At last, in April 2023 it was done: Akan is now locked, and a notice at the top of the still-active domain points people to the Twi Wikipedia and the Fante Incubator, which Robert helped start. The Fante Incubator is growing rapidly, and may be approved soon to become a full-fledged edition of Wikipedia.
Soon after the closing was performed, the people in the Ghanaian Wikipedians Telegram group expressed a lot of happiness about it. 2020 Wikipedian of the year Sandister Tei wrote:
Having an Akan Wikipedia made no sense, and it blocked or confused contributors/readers who were (or would be in the future) trying to engage with the other dialects like Twi, Fante, Nzema and Bono under Akan. It had been a pain point for us for years. It was problematic for collaborators of the sum of all human knowledge to get this knowledge wrong… This resolution is good progress worth sharing with all who worried about the problem at a point.
In the meantime, the Twi Wikipedia, thanks to the efforts of Robert and other contributors, has grown from about 600 articles in 2021 to more than 2700 in April 2023. The number of its readers has grown as well, from an average of 130,000 monthly visitors in 2021 to 280,000 in 2022.
Statistics of Twi Wikipedia readership from 2019 until February 2023. Taken from Wikistats.
There are more languages that are spoken by millions of people, but in which there is a dormant, inactive Wikipedia, or no Wikipedia at all. Robert’s example shows that with a bit of effort and love for one’s language, the same transformation and growth can happen in all of them.
Got your attention with that provocative title? Good.
No, I absolutely don’t want Wikipedia to be less Free in terms of copyright and licenses and all that. I wrote the Wikipedia:The Free Encyclopedia essay on the English Wikipedia, and I still totally support it.
With that out of the way, there’s another aspect of “Free” in the Wikipedia world, which is not frequently discussed, and I’ve just realized that it’s kind of important.
What is the most translated book in the world? The Bible, of course. Why is it the most translated book? Because there are people who are emotionally attached to it, who want to spread it around the planet, and who are willing to donate money to organizations who translate and distribute it, and these organizations are actually good at what they do.
It’s not so important that it’s the Bible that happens to be the most translated book. If it wasn’t the Bible, it would be something else: some other religious book, or The Declaration of Human Rights, or The Communist Manifesto, or Romance of the Three Kingdoms, or Twelfth Night, or The Little Prince. I mean, what is the Bible? It’s a book; it has a beginning and an end. Sure, different Christian confessions can argue about the Apocrypha, the sequence of the books, the inclusion of some verses, the translation of some theologically significant words, and so on, but this is also completely unimportant for our issue; most of the Bible is the same in all confessions.
Now, because I love translation, I quite often read about organizations who engage in translating the Bible: Wycliffe, SIL, JW, Latter-Day Saints, etc. Wycliffe, for example, can publish an image like this one:
They can speak about “a full Bible” and to give a count of how many languages have one, because they know what the Bible is.
It’s not about religion. You could just as well make such a report about Alice’s Adventures in Wonderland or about Things Fall Apart. And you don’t even have to make such a report about these famous, iconic books: I’m sure that in the marketing department of every Hollywood studio there are people who make dozens of reports like this about translating movies every year. Like books, movies have a beginning and an end. So it’s really not about the Bible; the Bible just happens to be one book that attracts exceptional fame and emotion, so it’s useful as an example.
But could you make such a report about Wikipedia? Not quite.
That’s because we don’t really know what Wikipedia is. Unlike a book, it doesn’t have a clear beginning and an end. In languages that have an active Wikipedia editing community, it is changing so frequently, and so differently from other languages, that we can’t define what is “a Wikipedia” in a way that “translating Wikipedia” would mean “writing all the same things, just in another language”. You could perhaps say this about a single Wikipedia article, and you’d have challenges even with that, but you can’t say it about a whole Wikipedia.
We can make technical statements: “There is a Wikipedia in English; There is a Wikipedia in Japanese; There is a Wikipedia in Zulu; There is a Wikipedia in Hungarian”. For each of these languages, there is a *.wikipedia.org domain, and it leads to a website that has the same name and the same puzzle globe logo, and runs on more or less the same software platform. There is some overlap in the articles that each of these sites has, but defining this overlap is too elusive.
Having a domain does not necessarily mean that there is a full-fledged Wikipedia in a language. A Wikipedia needs articles and readers. For example: Intuitively, we can say that while the Zulu Wikipedia is not worthless, it is not nearly as useful to Zulu speakers as the Hungarian Wikipedia is to Hungarian speakers, even though both languages have a comparable number of speakers. The one in Zulu has much fewer articles and readers than the one in Hungarian.
So does it mean that to be useful, the Zulu Wikipedia has to translate all the articles from the Hungarian Wikipedia, or the English one? No. I have proof, which is also based on my intuition and not on data, but I doubt that anyone will reject it, even though it’s somewhat paradoxical. I’d argue that the Hungarian Wikipedia is more or less as useful for Hungarian speakers as the English Wikipedia, even though it has much fewer articles. Within the country of Hungary, the Hungarian Wikipedia gets more than twice the pageviews than the English Wikipedia does. This probably means that the Hungarian Wikipedia editors are quite good at guessing what things do other Hungarian speakers want to read about, and in writing articles about them, so Hungarian speakers are usually able to find lots of things they need there without having to search for it in another language (or giving up because they don’t know any other language). Unfortunately, the Zulu Wikipedia is not there yet. I know a few Zulu Wikipedians and they are wonderful, but it will take some time and effort to make the Zulu Wikipedia into an online encyclopedia that is as useful and robust as the one in Hungarian, or Hebrew, or English.
But still, even though it’s based on some data, all of that is mostly intuition. It all sounds correct, but we have no precisely defined way to measure it comprehensively. We can precisely answer the question “how many languages have the Bible” or “how many languages have Winnie-the-Pooh” because we know what these books are, but we cannot precisely and usefully answer the question “how many languages have a Wikipedia”, because we don’t know what “a Wikipedia” is.
We can know this about a certain small part of Wikipedia: the localization of its software platform, MediaWiki. The list of strings to translate is well-defined. It often changes, because the software is being actively developed, but on any given day you can easily get a report that says: “Language X has Y% of the software needed to run Wikipedia”. That’s because the software is largely the same in all the languages (with some caveats); in other words, it has a beginning and an end.
A screenshot of a part of the report. Good work, translators to Arabic, Belarusian, German, Persian, French, Macedonian, Norwegian Bokmål, Dutch, Russian, and Turkish! (Also Hebrew, but a lot of that is done by yours-truly, so it’s weird to praise myself.)
OK, but the software is not that useful without the content. So why don’t we similarly define what articles must exist in a Wikipedia to determine that it is a Wikipedia, and that it’s actually useful?
Well, because of that other subtle freedom: The community of Wikipedia writers in every language is free to decide which articles they want to write, and what is encyclopedically notable or non-notablefor them. This freedom is generally a Good Thing: People who live in different countries and speak different languages have different needs and interests, and no one in their right mind should want to enforce a list of what Wikipedia articles must exist on people from another culture.
But what if we could suggest such a list? In a way, we already do: There’s the somewhat-famous List of articles every Wikipedia should have. That list has a bunch of problems, however.
It is manually curated by… some people, with whose Wikipedia usernames I’m not familiar. I have nothing against them; the work they do may be very good, but I don’t feel like they are widely recognized as an authority. I might be wrong.
In addition, how is this list used structurally? What can you do with it, other than just read it? There are some bots and Wikidata queries that measure how well does the Wikipedia in every language cover the topics on that list. For example, there’s an automatic report of which articles from this list are missing in each language. While these tools may be convenient for experienced Wikipedians, I doubt that they are good at encouraging masses of potential editors to improve the content coverage in their language. (Again, do correct me if I’m wrong.)
Finally, it is just one such list. While the articles on it may indeed be important for all of humanity, people who speak different languages will need additional articles about things that interest them. Of course, this list doesn’t try to enforce its own exclusivity, and people are free to create additional custom lists that match their cultural and regional needs… but that brings us back to the problem: Sure, freedom to make your own lists is good and essential, but if people in every language have to reinvent the wheel and do it manually, it’s difficult and inefficient. And if it’s not done systematically and uniformly for all languages, you can only use intuition and not precise measurement to decide whether a language really has a Wikipedia or not.
And that, I’d say, is too much freedom. Wikipedia should be a bit less free in this regard. I’ll repeat: No, not to force people to write about things that other people in another country decided that they must write, but to have a global way to decide on a task list, of what should be done and what was done already. A nudge.
Do I have anything to suggest as a fix to this problem? Not much, except identifying it: We cannot usefully define a Wikipedia, and we can only know it when we see it.
Still, what I can think about is a two-part approach. The first part is formulating a global community policy to determine at which point does a Wikipedia become really useful. Don’t call it “rules”; call it “recommended guidelines for measurable sustainable growth”. Sounds bureaucratic in the style of U.N. and E.U., but read it carefully—I actually mean it. If done well, it might work. By “work”, I mean “get Wikipedia in all languages to grow and become more useful for people who speak these languages”.
It would include things such as:
A global list of articles that every language should have, with globally important topics. Notice: should, not must! The “List of articles every Wikipedia should have” can probably be a starting point, but the discussion about forming and updating it should probably be wider, more structured, and endorsed by some recognized community body, such as the Board or the Language committee.
A local list of articles that a language should have. The list itself will be different in each language, but the method to build it will be the same, so that languages can be compared.
The expected length of each article and some heuristic quality markers: section headings, references, links, etc.
An expected number of how many people write these articles, proportinally to the number of people who speak the language.
An expected number of how many people read these articles, proportinally to the number of people who speak the language (this can be measured by counting pageviews in regions where each language is spoken).
A method to update these lists and the policy itself.
And the second part is building structured, integrated technical tools that help implement that policy:
Entering the lists into a structured database (that is, not a free-form wiki page).
Tracking the progress of the Wikipedia in each language from being just a domain with some test articles fresh out of the Incubator to being a full-fledged Wikipedia that people regularly edit, read, and rely on. “Tracking” means auto-generated tables, charts, and progress bars.
Nudging people to come in and contribute to achieving that goal for their language by writing or translating articles, improving (“wikifying”) existing articles, and so on.
Why would people want to coöperate with these rules and use them? Maybe they won’t, and that’s OK. But from my years of talking to people from all over the world who want to create a Wikipedia in their language, or who want to develop the one that they have, I repeatedly heard that what they want is a Wikipedia, mostly like the one in big languages such as English, French, Indonesian, or Russian, but in their language. It’s unreasonably difficult to do it without first defining what a Wikipedia is, and doing it in a way that relies on definitions and guidelines and not only on intuition and freedom.
People who translate MediaWiki and other pieces of software with which I am involved to languages of India, Philippines, African countries, and other places, often ask me: Should we translate to pure native neologisms, or reuse English words?
Linguistic purism is quite common in translation in general, and not only in software. I heard of a study that compared a corpus of texts written originally in Hebrew with a corpus of translated texts. The translated texts had considerably fewer loanwords. This may be surprising at first: how can translated texts have fewer loanwords?
But actually this makes sense: A translator is not creating a story, but re-telling a story that already exists. A good translator is supposed to understand the original story well first, and after understanding it, the translator is supposed to retell it in the target language. Many translators use the time that they don’t invest in creating the story itself to make the translation “purer” than the target language actually is.
A text that is originally written in Hebrew expresses how Hebrew-speaking people actually talk. Despite a history of creating many neologisms, some of which were successful, Hebrew speakers also use a lot of loanwords from English, Arabic, German, Russian, French, and other languages.
And that’s totally OK. Loanwords don’t “degrade” or “kill” a language, as some people say. Certainly not by themselves. English has many, many words from French, Latin, Norwegian, Greek, and other languages, and they didn’t kill it. Quite the contrary: English is one of the most successful languages in the world.
A good original writer creates verisimilitude, naturally or intentionally, by using actual living language. And actual living language has loan words. More in some languages, fewer in others, but it happens everywhere.
Software localization is a bit different from books, however. Books, both fiction and non-fiction, are art. At least to some degree, the language itself is an expressive tool there.
Software user interfaces are less about art and more about function. A piece of software is supposed to be usable and functional, and as easy and obvious to learn and use as possible. The less people need to learn it, the closer it is to perfection. And localized software is no different: it must, above all, be functional.
Everything else is secondary to usability. If the translation is beautiful, but the software can’t be used, the job is not done.
And this is the thing that is supposed to guide you when choosing whether to translate a term as a native word, possibly a neologism, or to transliterate a foreign term and make it a loanword: Will the user understand it and be able to use the software?
The choice is not as obvious as some people may think, however. Some people may think that loaning a word makes more sense because it’s already familiar, and this will make the software familiar.
But always ask yourself: Familiar to whom?
The translator, pretty much by definition, is supposed to know the source language, and to be able to use the software in the source language. Most often the source language is English. So most likely the translator is familiar with the source terminology.
But will the user be familiar with it?
The translated piece of software is supposed to be usable by people who aren’t familiar with that software in the source language, and, very importantly, by people who don’t know the source language at all.
So if you translate words like “log in”, “account”, “file”, “proxy”, “feed”, and so on, by simply transliterating them into the target language because they are “familiar” in this form, ask yourself: are they also familiar to people who don’t know English and who aren’t experienced with using computers?
Some Hebrew software localizers translate “proxy” as something like “intermediary server” (שרת מתווך), and some just write “proxy” in transliteration (פרוקסי). The rationale for “proxy” is usually this: “everyone knows what ‘proxy’ is, and no one knows what an intermediary server is”.
But is it really everyone? Or maybe it’s just you and your software developer friends?
To people who aren’t software developers, the function of “proxy” is pretty much as obscure as the function of “intermediary server”… or is it? Because the fully translated native term actually says something about what this thing does in familiar words.
Of course, if you are really sure that a foreign term is widely familiar to all people, then it’s OK to use, and often it’s better than using a “pure” neologism.
And that’s why I put “pure” in double quotes: The “purity” itself is not important. Functionality and usability are above all. Sometimes “purity” makes usability better. Sometimes it doesn’t. It’s not an exact science.
I’ll go even further: More often than many people would think, pondering the meaning and choosing a correct translation for a software user interface term may start fruitful conversations about the design of the original software and uncover usability flaws that affect everyone, including the people who use the software in English.
There are thousands of useful bug reports in MediaWiki and in other software projects in which I am involved that were filed by localizers who had translation difficulties. Many of these bugs were fixed, improving the experience for users in English and in all languages.
To sum up:
Purism shouldn’t be the most important goal, but it should be one of the optional tools that the translator uses.
Purism is neither absolutely bad nor absolutely good. It can be useful when used wisely in context, case by case.
Usability should be the most important goal of software localization.
Usability means usability for all, not just for your colleagues.
Localizers can improve the whole software in more ways than just translating strings.
As you probably already know, Wikipedia is a website. A website has two components: the content and the user interface. The content of Wikipedia is the articles, as well as various discussion and help pages. The user interface is the menus around the articles and the various screens that let editors edit the articles and communicate to each other.
Another thing that you probably already know is that Wikipedia is massively multilingual, so both the content and the user interface must be translated.
Translation of articles is a topic for another post. This post is about getting all the user interface translated to your language, and doing it as quickly, easily, and efficiently as possible.
The most important piece of software that powers Wikipedia and its sister projects is called MediaWiki. As of today, there are more than 3,800 messages to translate in MediaWiki, and the number grows frequently. “Messages” in the MediaWiki jargon are strings that are shown in the user interface. Every message can and should be translated.
In addition to core MediaWiki, Wikipedia also uses many MediaWiki extensions. Some of them are very important because they are frequently seen by a lot of readers and editors. For example, these are extensions for displaying citations and mathematical formulas, uploading files, receiving notifications, mobile browsing, different editing environments, etc. There are more than 5,000 messages to translate in the main extensions, and over 18,000 messages to translate if you want to have all the extensions translated, including the most technical ones. There are also the Wikipedia mobile apps and additional tools for making automated edits (bots) and monitoring vandalism, with several hundreds of messages each.
Translating all of it probably sounds like an impossibly enormous job. It indeed takes time and effort, but the good news are that there are languages into which all of this was translated completely, and it can also be completely translated into yours. You can do it. In this post I’ll show you how.
A personal story
In early 2011 I completed the translation of all the messages that are needed for Wikipedia and projects related to it into Hebrew. All. The total, complete, no-excuses, premium Wikipedia experience, in Hebrew. Every single part of the MediaWiki software, extensions and additional tools was translated to Hebrew. Since then, if you can read Hebrew, you don’t need to know a single English word to use it.
I didn’t do it alone, of course. There were plenty of other people who did this before I joined the effort, and plenty of others who helped along the way: Rotem Dan, Ofra Hod, Yaron Shahrabani, Rotem Liss, Or Shapiro, Shani Evenshtein, Dagesh Hazak, Guycn2 and Inkbug (I don’t know the real names of the last three), and many others. But back then in 2011 it was I who made a conscious effort to get to 100%. It took me quite a few weeks, but I made it.
However, the software that powers Wikipedia changes every single day. So the day after the translations statistics got to 100%, they went down to 99%, because new messages to translate were added. But there were just a few of them, and it took me only a few minutes to translate them and get back to 100%.
I’ve been doing this almost every day since then, keeping Hebrew at 100%. Sometimes it slips because I am traveling or because I am ill. It slipped for quite a few months in 2014 because my first child was born and a lot of new messages happened to be added at about the same time, but Hebrew got back to 100%. It happened again in 2018 for the same happy reason, and went back to 100% after a few months. And I keep doing this.
With the sincere hope that this will be useful for helping you translate the software that powers Wikipedia completely to your language, let me tell you how.
Preparation
First, let’s do some work to set you up.
If you haven’t already, create a translatewiki.net account at the translatewiki.net main page. First, select the languages you know by clicking the “Choose another language” button (if the language into which you want to translate doesn’t appear in the list, choose some other language you know, or contact me). After selecting your language, enter your account details. This account is separate from your Wikipedia account, so if you already have a Wikipedia account, you need to create a new one. It may be a good idea to give it the same username.
After creating the account you have to make several test translations to get full translator permissions. This may take a few hours. Everybody except vandals and spammers gets full translator permissions, so if for some reason you aren’t getting them or if it appears to take too much time, please contact me.
Make sure you know your ISO 639 language code. You can easily find it on Wikipedia.
Go to your preferences, to the Editing tab, and add languages that you know to Assistant languages. For example, if you speak one of the native languages of South America like Aymara (ay) or Quechua (qu), then you probably also know Spanish (es) or Portuguese (pt), and if you speak one of the languages of Indonesia like Javanese (jv) or Balinese (ban), then you probably also know Indonesian (id). When available, translations to these languages will be shown in addition to English.
The translatewiki.net website hosts many projects to translate beyond stuff related to Wikipedia. It hosts such respectable Free Software projects as OpenStreetMap, Etherpad, MathJax, Blockly, and others. Also, not all the MediaWiki extensions are used on Wikimedia projects. There are plenty of extensions, with thousands of translatable messages, that are not used by Wikimedia, but only on other sites, but they use translatewiki.net as the platform for translation of their user interface.
It would be nice to translate all of it, but because I don’t have time for that, I have to prioritize.
On my translatewiki.net user page I have a list of direct links to the translation interface of the projects that are the most important:
Core MediaWiki: the heart of it all
Extensions used by Wikimedia: the extensions on Wikipedia and related sites. This group is huge, and I prioritize it further; see below.
MediaWiki Action Api: the documentation of the API functions, mostly interesting to developers who build tools around Wikimedia projects
Wikipedia Android app
Wikipedia iOS app
Installer: MediaWiki’s installer, not used on Wikipedia because MediaWiki is already installed there, but useful for people who install their own instances of MediaWiki, in particular new developers
Intuition: a set of tools, like edit counters, statistics collectors, etc.
Pywikibot: a library for writing bots—scripts that make useful automatic edits to MediaWiki sites.
I usually don’t work on translating other projects unless all the above projects are 100% translated to Hebrew. I occasionally make an exception for OpenStreetMap or Etherpad, but only if there’s little to translate there and the untranslated MediaWiki-related projects are not very important.
Priorities, part 2
So how can you know what is important among more than 18,000 messages from the Wikimedia universe?
Start from MediaWiki most important messages. If your language is not at 100% in this list, it absolutely must be. This list is automatically created periodically by counting which 600 or so messages are actually shown most frequently to Wikipedia users. This list includes messages from MediaWiki core and a bunch of extensions, so when you’re done with it, you’ll see that the statistics for several groups improved by themselves.
Now, if the translation of MediaWiki core to your language is not yet at 18%, get it there. Why 18%? Because that’s the threshold for exporting your language to the source code. This is essential for making it possible to use your language in your Wikipedia (or Incubator). It will be quite easy to find short and simple messages to translate (of course, you still have to do it carefully and correctly).
Some technical notes
Have you read the general localization guide for Mediawiki? Read it again, and make sure you understand it. If you don’t, ask for help! The most important section, especially for new translators, is “Translation notes”.
A super-brief list of things that you should know:
Many messages use symbols such as ==, ===, [[]], {{}}, *, #, and so on. This is wiki syntax, also known as “wikitext” or “wiki markup”. It is recommended to become familiar with some wiki syntax by editing a few pages on another wiki site, such as Wikipedia, before translating MediaWiki messages at translatewiki.
“[[Special:Homepage]]” adds a link to the page “Special:Homepage”. “[[Special:Homepage|Homepage]]” adds a link to the page “Special:Homepage”, but it will be displayed as “Homepage”. In such cases, you are usually not supposed to translate the text before the | (pipe), but you should translate the text after it. For example, in Russian: “[[Special:Homepage|Домашняя страница]]”. When in doubt, check the documentation in the sidebar.
$1, $2, $3: These are known as parameters, placeholders, or variables. They are replaced in run time, usually by numbers of names. Copy them as they are, and put them in the right place in the sentence, where it is right for your language. Always check the documentation in the sidebar to understand with what will they be replaced.
If you see something like “$1 {{PLURAL:$1|page|pages}}” in a translatable message, this means that the word will be shown according to the value of the variable $1. Note that you must not change the “PLURAL:$1” part, but you must translate the “page|pages” part.
If you see something else in curly brackets, it’s probably a “magic word”. Check the documentation to understand it. You usually don’t translate the thing in the beginning, such as {{SITENAME, {{GENDER, etc., but you sometimes need to translate things towards the end. See the localization guide for full documentation!
Learn to use the project selector at the top of the translation interface. Projects are also known as “Message groups”. For example, each extension is a message group, and some larger extension, such as Visual Editor, are further divided into several smaller message groups. Using the selector is very simple: Just click “All” next to “Message group”, and use the search box to find the component that you want to translate, such as “Visual Editor” or “Wikibase”. Clicking on a message group will load the untranslated messages for that group.
The “Extensions used by Wikimedia” group is divided into several more subgroups. The important one is “Extensions used by Wikimedia – Main”, which includes the most commonly used extensions. Other subgroups are:
“Advanced”: extensions that are used only on some wikis, or are useful only to administrators and other advanced users. This should be the first subgroup you translate after you complete the “Main” subgroup.
“Fundraising”: extensions used for collecting donations for the Wikimedia Foundation.
“Legacy”: extensions that are still installed on Wikimedia sites, but are going to be removed. You can most likely skip this subgroup completely.
“Media” includes advanced tools for media files curating and uploading, especially on Wikimedia Commons.
“Technical”: this is mostly API documentation for various extensions, which is shown on the ApiHelp and ApiSandbox special pages. It is very useful for developers of gadgets, bots, and other software, but not necessary for other users. This group also includes several other very advanced extensions that are used only by a few people. You should translate these messages some day, but it’s OK to do it later.
“Upcoming”: these are extensions that are not yet widely installed on Wikimedia sites, but are going to be installed soon. Translating them is a pretty good idea, because they are usually very new, and may include some confusing messages. The earlier you report these confusing messages to the developers, the better!
“Wikivoyage”: extensions used only on Wikivoyage sites. Translate them if there is a Wikivoyage site in your language, or if you want to start one.
There is also a group called “EXIF Tags”. It’s an advanced part of core MediaWiki. It mostly includes advanced photography terminology, and it shows information about photographs on Wikimedia Commons. If you are not sure how to translate these messages, ask a professional photographer. In any case, it’s OK to do it later, after you completed more important components.
Getting things done, one by one
Once you have the most important MediaWiki messages 100% and at least 18% of MediaWiki core is translated to your language, where do you go next?
I have surprising advice.
You need to get everything to 100% eventually. There are several ways to get there. Your mileage may vary, but I’m going to suggest the way that worked for me: Complete the easiest piece that will get your language closer to 100%! For me this is an easy way to remove an item off my list and feel that I accomplished something.
But still, there are so many items at which you could start looking! So here’s my selection of components that are more user-visible and less technical. The list is ordered not by importance, but by the number of messages to translate (as of October 2020):
Vector: the default skin for desktop and laptop computers
Minerva Neue: the skin for mobile phones and tablets
Babel: for displaying boxes on user pages with information about the languages that the user knows
Thanks: the extension for sending “thank you” messages to other editors
Universal Language Selector: the extension that lets people easily select the language they need from a long list of languages (disclaimer: I am one of its developers)
jquery.uls: an internal component of Universal Language Selector that has to be translated separately (for technical reasons)
Cite: the extension that displays footnotes on Wikipedia
Math: the extension that displays math formulas in articles
Wikibase Client: the part of Wikidata that appears on Wikipedia, mostly for handling interlanguage links
ProofreadPage: the extension that makes it easy to digitize PDF and DjVu files on Wikisource (this is relevant only if there is a Wikisource site in your language, or if you plan to start one)
I put MediaWiki core last intentionally. It’s a very large message group, with over 3000 messages. It’s hard to get it completed quickly, and actually, some of its features are not seen very frequently by users who aren’t site administrators or very advanced editors. By all means, do complete it, try to do it as early as possible, and get your friends to help you, but it’s also OK if it takes some time.
Getting all the things done
OK, so if you translate all the items above, you’ll make Wikipedia in your language mostly usable for most readers and editors. But let’s go further.
Let’s go further not just for the sake of seeing pure 100% in the statistics everywhere. There’s more.
As I wrote above, the software changes every single day. So do the translatable messages. You need to get your language to 100% not just once; you need to keep doing it continuously.
Once you make the effort of getting to 100%, it will be much easier to keep it there. This means translating some things that are used rarely (but used nevertheless; otherwise they’d be removed). This means investing a few more days or weeks into translating-translating-translating.
You’ll be able to congratulate yourself not only upon the big accomplishment of getting everything to 100%, but also upon the accomplishments along the way.
One strategy to accomplish this is translating extension by extension. This means, going to your translatewiki.net language statistics: here’s an example with Albanian, but choose your own language. Click “expand” on MediaWiki, then again “expand” on “MediaWiki Extensions” (this may take a few seconds—there are lots of them!), then on “Extensions used by Wikimedia” and finally, on “Extensions used by Wikimedia – Main”. Similarly to what I described above, find the smaller extensions first and translate them. Once you’re done with all the Main extensions, do all the extensions used by Wikimedia. This strategy can work well if you have several people translating to your language, because it’s easy to divide work by topic. (Going to all extensions, beyond Extensions used by Wikimedia, helps users of these extensions, but doesn’t help Wikipedia very much.)
Another fun strategy is quiet and friendly competition with other languages. Open the statistics for Extensions Used by Wikimedia – Main and sort the table by the “Completion” column. Find your language. Now translate as many messages as needed to pass the language above you in the list. Then translate as many messages as needed to pass the next language above you in the list. Repeat until you get to 100%.
For example, here’s an excerpt from the statistics for today:
Let’s say that you are translating to Georgian. You only need to translate 37 messages to pass Marathi and go up a notch (2555 – 2519 + 1 = 37). Then 56 messages more to pass Hindi and go up one more notch (2518 – 2463 + 1 = 56). And so on.
Once you’re done, you will have translated over 5600 messages, but it’s much easier to do it in small steps.
Once you get to 100% in the main extensions, do the same with all the Extensions Used by Wikimedia. It’s way over 10,000 messages, but the same strategies work.
Good stuff to do along the way
Invite your friends! You don’t have to do it alone. Friends will help you work more quickly and find translations to difficult words.
Never assume that the English message is perfect. Never. Do what you can to improve the English messages. Developers are people just like you are. There are developers who know their code very well, but who are not the best writers. And though some messages are written by professional user experience designers, many are written by the developers themselves. Developers are developers; they are not necessarily very good writers or designers, and the messages that they write in English may not be perfect. Also, keep in mind that many, many MediaWiki developers are not native English speakers; a lot of them are from Russia, Netherlands, India, Spain, Germany, Norway, China, France and many other countries. English is foreign to them, and they may make mistakes.
So if anything is hard to translate, of if there are any other problems with the English messages to the translatewiki Support page. While you are there, use the opportunity to help other translators who are asking questions there, if you can.
Another good thing is to do your best to try using the software that you are translating. If there are thousands of messages that are not translated to your language, then chances are that it’s already deployed in Wikipedia and you can try it. Actually trying to use it will help you translate it better.
Whenever relevant, fix the documentation displayed near the translation area. Strange as it may sound, it is possible that you understand the message better than the developer who wrote it!
Before translating a component, review the messages that were already translated. To do this, click the “All” tab at the top of the translation area. It’s useful for learning the current terminology, and you can also improve them and make them more consistent.
After you gain some experience, create or improve a localization guide in your language. There are very few of them at the moment, and there should be more. Here’s the localization guide for French, for example. Create your own with the title “Localisation guidelines/xyz” where “xyz” is your language code.
As in Wikipedia itself, Be Bold.
OK, so I got to 100%, what now?
Well done and congratulations.
Now check the statistics for your language every day. I can’t emphasize enough how important it is to do this every day. If not every day, then as frequently as you can.
The way I do this is having a list of links on my translatewiki.net user page. I click them every day, and if there’s anything new to translate, I immediately translate it. Usually there are just a few new messages to translate; I didn’t measure precisely, but usually it’s fewer than 20. Quite often you won’t have to translate from scratch, but to update the translation of a message that changed in English, which is usually even faster.
But what if you suddenly see 200 new messages to translate or more? It happens occasionally. Maybe several times a year, when a major new feature is added or an existing feature is changed. Basically, handle it the same way you got to 100% before: step by step, part by part, day by day, week by week, notch by notch, and get back to 100%.
But you can also try to anticipate it. Follow the discussions about new features, check out new extensions that appear before they are added to the Extensions Used by Wikimedia group, consider translating them when you have a few spare minutes. At the worst case, they will never be used by Wikimedia, but they may be used by somebody else who speaks your language, and your translations will definitely feed the translation memory database that helps you and other people translate more efficiently and easily.
Consider also translating other useful projects: OpenStreetMap, Etherpad, Blockly, Encyclopedia of Life, etc. Up to you. The same techniques apply everywhere.
What do I get for doing all this work?
The knowledge that thanks to you, people who read in your language can use Wikipedia without having to learn English. Awesome, isn’t it? Some people call it “Good karma”. Also, the knowledge that you are responsible for creating and spreading the terminology in your language for one of the most important and popular websites in the world.
Oh, and you also get enormous experience with software localization, which is a rather useful and demanded job skill these days.
Is there any other way in which I can help?
Yes!
If you find this post useful, please translate it to other languages and publish it in your blog. No copyright restrictions, public domain (but it would be nice if you credit me and send me a link to your translation). Make any adaptations you need for your language. It took me years of experience to learn all of this, and it took me about four hours to write it. Translating it will take you much less than four hours, and it will help people be more efficient translators.
Here’s a story of how I tried to remove a fake story marginally related to COVID-19 from Wikipedia, and, at least for now, achieved the opposite and contributed to its dissemination and perpetuation.
On a BBC-produced podcast (in Russian) I heard a story about Lupe Hernández, a nurse who allegedly invented hand sanitizer. The story was born in a 2012 Guardian article, which was subsequently quoted by viral Facebook posts and a bunch of news sites in Spanish and a bunch of other languages, and even mention in an academic nursing book published by Springer. In the last few months hand sanitizer became more popular than ever, and so the story regained popularity.
When contacted for confirmation, the original Guardian story’s author said that “she couldn’t remember the source, and that her notebooks are in storage facility she currently can’t get to”.
The podcast, as well as a thorough LA Times article, conclude that the whole story is probably an urban legend and that the person probably never existed. No one was even sure whether it’s a woman or a man, even though the original story said “she”.
The podcast did mention that there is a very short Wikipedia article. I proposed it for deletion. The result of the deletion discussion was that the article was kept and renamed to “Lupe Hernández hand sanitizer legend”.
Before it was renamed in the English Wikipedia to be an article about a legend, it was also translated to Spanish and French, as an article about “Guadalupe Hernández”, a female nurse who invented hand sanitizer, even though zero sources say that her name was actually “Guadalupe”. Sure, you can assume that “Lupe” is short for “Guadalupe”, as some imaginative writers did, but why do we do it on Wikimedia sites?
I’m still of the firm opinion that the subject should be completely removed from Wikipedia in all languages, as well as from Wikidata, but there’s only so much I can do about this. If any of you know French or Spanish, can you please make sure the articles in your languages are not too awful, or perhaps consider proposing them for deletion?
And if you think I’m badly wrong about it all, please do tell me, too.
The Persistence of Poverty, which is today’s episode of NPR’s famous “Indicator” podcast, made me think of how small things that happened long ago in the history of Wikipedia and other Wikimedia wiki sites still affect us, for better or worse.
Here are some examples.
Example one: People didn’t want to have full copies of historical documents on the English Wikipedia, because they are not encyclopedic articles. So they created a whole separate wiki for it, called “Primary Sources Wikipedia”: “ps.wikipedia.org”. It turned out that this would be the URL for the Wikipedia in the Pashto language, which has the ISO 639 code “ps”, so it was renamed to Wikisource, becoming Wikimedia’s first non-Wikipedia wiki. The movement wasn’t even called “Wikimedia” then—the organization was created later. Later, Wiktionary, Wikibooks, WikiCommons, and other projects joined. And Wikisource and all of these other projects are awesome, but now this also has the side effect of having to have some challenging discussions between the Foundation and the community about how non-Wikipedia wikis should be branded in the long term.
Example two: A French Wikipedia editor who is curious about Ancient Egypt wanted to insert Egyptian hieroglyphics into Wikipedia articles, and he happened to know some PHP, so he wrote the Wikihiero extension, which is installed on all the wikis. Because it’s an extension that adds its own wiki syntax, Visual Editor shows a button to insert Hieroglyphics on every page, including the page about Astronomy on Wikiversity, which doesn’t have much to do with Ancient Egypt. This is not bad—this is mostly very good. What is bad is that the Visual Editor doesn’t have a button to insert infoboxes or “citation needed” tags, even though they are far more common than hieroglyphics, because they are implemented as templates and not as PHP, and Visual Editor handles all templates as one generic type of object. (If you are wondering how can this get fixed, the first necessary step in that direction is described on the page Global templates on mediawiki.org.)
Example three: Some people didn’t like that too many wikis are created in new languages and stay inactive, so they wanted a proper way to prove that people plan to be active editors. So they created the “Incubator” wiki, where people would show they are serious by writing the first bunch of articles. For various technical reasons, using it was more difficult than using a usual Wikipedia, but they probably quietly assumed that everybody who wants to create a Wikipedia in a new language is experienced in editing Wikipedia in English or Italian or some other big language, so almost no one ever bothered to improve it. By now, we know that that assumption was tragically wrong: most people who want to create a Wikipedia in a new language are not experienced in editing in other languages, so they are newest and the least experienced editors, but they get the most complicated user interface. (If you are wondering how can this get fixed, see this page on Phabricator.)
Yes, I’m oversimplifying all of these stories for brevity. And I’m not implying any malice or negligence in any of the cases here. These were good people with good intentions, who made assumptions that were reasonable for the time.
It’s just a shame that the problems they created are proving more difficult to fix as the time goes by.
Some time ago I celebrated a birthday in an Italian restaurant in Haifa, and I saw a pack of pasta of a curious shape on a shelf there. I asked whether they serve it or sell it.
“No”, they told me, “it’s just a display”.
This answer didn’t satisfy me.
I added the pasta’s name, Busiate, to my shopping list.
I searched for it in a bunch of stores. No luck.
I googled for it and found an Israeli importer of this pasta. But that importer only sell in bulk, in crates of at least 12 items. That’s too much.
And of course, I searched Wikipedia, too. There’s an article about Busiate in the English Wikipedia. There also an article about this pasta in Arabic and in Japanese, but curiously, there’s no article about it in the Wikipedia in the Italian language, nor in the Sicilian language, given that this type of pasta is Sicilian.
I also translated all the names of the Wikidata properties that are used on these items to Hebrew. I usually do this when I do something with any Wikidata item: I only need to translate these property names once, and after that all the people who use Wikidata in Hebrew will see items in which these properties are used in Hebrew. There are more than 6000 properties, and the number is constantly growing, so it’s difficult to have everything translated, but every little translation makes the experience more completely translated for everyone.
I added references to the Wikidata item about the sauce. Wikidata must have references, too, and not only Wikipedia. I am not enthusiastic about adding random recipe sites that I googled up as references, but luckily, I have The Slow Food Dictionary of Italian Regional Cooking, which I bought in Italy, or more precisely in Esino Lario, where I went for the 2016 Wikimania conference.
Now, a book in Wikidata is not just a book. You need to create an item about the book, and another item about the edition of a book. And since I created those, I create Wikidata items for the dictionary’s original Italian author Paola Gho, for the English translator John Irving, and for the publishing house, Slow Food.
And here’s where it gets really nerdy: I added each of the sauce’s ingredients as values of the “has part” property, and added the dictionary as a reference for each entry. I initially thought that it’s overdone, but you know what?—When we’ll have robot cooks, as in the movie I, Robot, busiati col pesto trapanese will be one of the first things that they will know how to prepare. One of the main points of Wikidata is that it’s supposed to be easy to read for both people and machines.
And since I have a soft spot for regional languages, I also added the sauce’s Sicilian name under the “native label” property: pasta cull’àgghia. The aforementioned Slow Food Dictionary of Italian Regional Cooking actually does justice to the regional part in its title, and gives the names of the different food items in the various regional languages of Italy, so I could use it as a reliable source.
And I translated the Wikipedia article into Hebrew: בוזיאטה.
And I also created the “Sicilian cuisine” category in the Hebrew Wikipedia. A surprisingly large number of articles already existed, filed under “Italian cuisine”: Granita, Arancini, Cannoli, and a few others. Now they are organized under Sicilian cuisine. (I hope that some day Wikipedia categories will be managed more automatically with the help of Wikidata, so that I wouldn’t have to create them by hand.)
Finally, I found the particular issue of the Gazzetta Ufficiale of the Italian Republic, in which busiati col pesto trapanese was declared as a traditional agricultural food product, and I added that issue as a reference to the Wikidata item, as well.
And all of this yak shaving happened before I even tasted the damn thing!
So anyway, I couldn’t find this pasta anywhere, and I couldn’t by it from the importer’s website, but I wanted it really badly, so I called the importer on the phone.
They told me they don’t have any stores in Jerusalem that buy from them, but they suggested checking a butcher shop in Mevaseret Tsiyon, a suburb of Jerusalem. Pasta in a butcher shop… OK.
So I took a bus to Mevaseret, and voila: I found it there!
And I made Busiate, and I made the sauce! It’s delicious and totally worth the effort.
Of course, I could just eat it without editing Wikipedia and Wikidata on the way, but to me that would be boring.
My wife and my son loved it.
These are the busiate with pesto alla trapanese that I made at home. I uploaded this photo to Wikimedia Commons and added it to the English Wikipedia article as an illustration of how Busiate are prepared. I wonder what do Wikipedians from Sicily think of it.
There is a story behind every Wikipedia article, Wikidata item, and Commons image. Millions and millions of stories. I wrote mine—you should write yours!
To celebrate this, I am happy to make a little announcement: It is now possible to write in all the Wikipedias of all the languages of Africa, with all the special letters that are difficult to find on common keyboards. You can do it on any computer, without buying any new equipment, installing any software, or changing operating system preferences. Please see the full list of languages and instructions.
This release completes a pet project that I began a year ago: to make it easy to write in all the languages of Africa in which there is a Wikipedia or an active Wikipedia Incubator.
Most of these languages are written in the Latin alphabet, but with addition of many special letters such as Ŋ, Ɛ, Ɣ, and Ɔ, or letters with accents such as Ũ or Ẹ̀. These letters are hard to type on common keyboards, and in my meetings with African people who would write in Wikipedia in their language this is very often brought up as a barrier to writing confidently.
Some of these languages have keyboard layouts that are built into modern operating systems, but my experience showed me that to enable them one has to dig deep in the operating system preferences, which is difficult for many people, and even after enabling the right thing in the preferences, some keyboards are still wrong and hard to use. I hope that this will be built into future operating system releases in a more convenient way, just as it is for languages such as French or Russian, but in the mean time I provide this shortcut.
The new software released this week to all Wikimedia sites and to translatewiki.net makes it possible to type these special characters without installing any software or pressing any combining keys such as Ctrl or Alt. In most cases you simply need to press the tilde character (~) followed by the letter that is similar to the one you want to type. For example:
Ɓ is written using ~B
Ɛ is written using ~E
Ɔ is written using ~O
… and so on.
Some of these languages are written in their own unique writing systems. N’Ko and Vai keyboards were made by myself, mostly based on ideas from freely licensed keyboard layouts by Keyman. (A keyboard for the Amharic language, also written with its own script, has had keyboards made by User:Elfalem for a while. I am mentioning it here for completeness.)
This release addresses only laptop and desktop computers. On mobile phones and tablets most of these languages can be typed using apps such as Gboard (also in iPhone), SwiftKey (also on iPhone), or African Keyboard. If you aren’t doing this already, try these apps on your phone, and start exchanging messages with your friends and family in your language, and writing in Wikipedia in your language on your phone! If you are having difficulties doing this, please contact me and I’ll do my best to help.
Mahuton Possoupe (Benin), with whom I made the first of these keyboards, for the Fon language, at the Barcelona Hackathon.
Kartik Mistry, Santhosh Thottingal (India), Niklas Laxström (Finland), and Petar Petkovich (Serbia), who reviewed the numerous code patches that I made for this project.
This is quite a big release or code. While I made quite a lot of effort to test everything, code may always have bugs: missing languages, wrong or missing letters, mistakes in documentation, and so on. I’ll be happy to hear any feedback and to fix the bugs.
And now it’s all up to you! I hope that these keyboard layouts make it easier for all of you, African Wikimedians, to write in your languages, to write and translate articles, and share more knowledge!
Again, happy Africa day!
The full list of languages for which there is now a keyboard in ULS and jquery.ime:




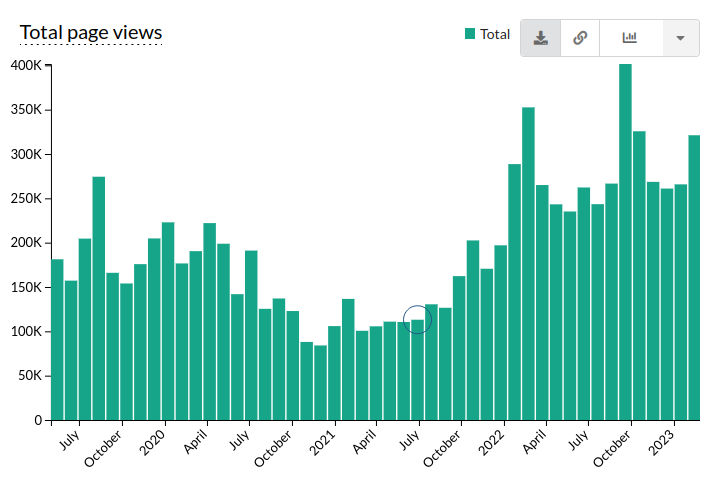

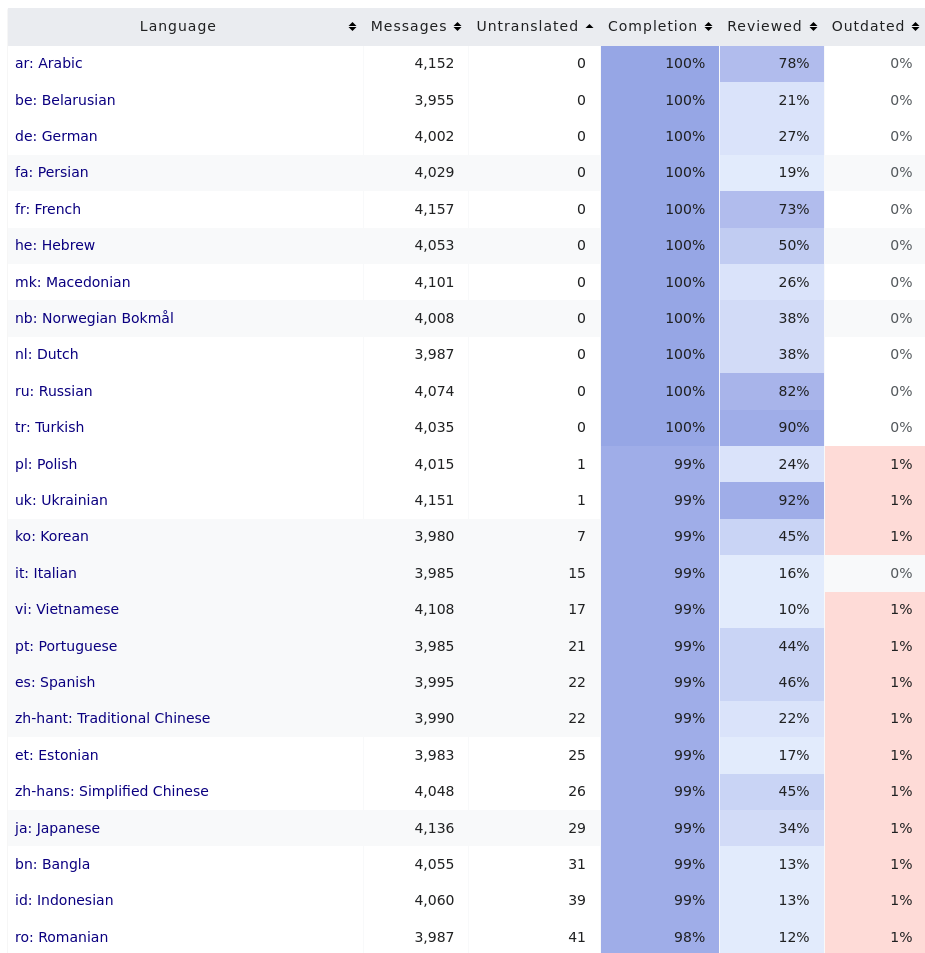


{kind=link}